
Host Your Own CoPilot
GitHub Co-pilot is a fantastic tool. However, it along with some of its other enterprise-grade alternatives such as SourceGraph Cody and Amazon Code Whisperer has a number of rather annoying downsides. The first is of course costing cold hard subscription cash in a world where LLMs are being commoditized. The second is the fact that by using coding co-pilots, you are essentially party to exfiltration of your own codebase to another party. For example, SourceGraph Cody runs on Anthropic’s Claude under the hood by default, and GitHub CoPilot runs on an OpenAI GPT based LLM under-the-hood. This can be an absolute dealbreaker for people and/or companies that value privacy and security.
Thankfully, for folks (and enterprises) who would rather self-host their own co-pilots, as of this writing, there are some quite good open source and open weight code generation LLMs available. For example DeepSeek-Coder-V2 at the time of its release (June 24, 2024) was on par with GPT4 Turbo.1
DeepSeek-Coder-V2 is pretty darn good
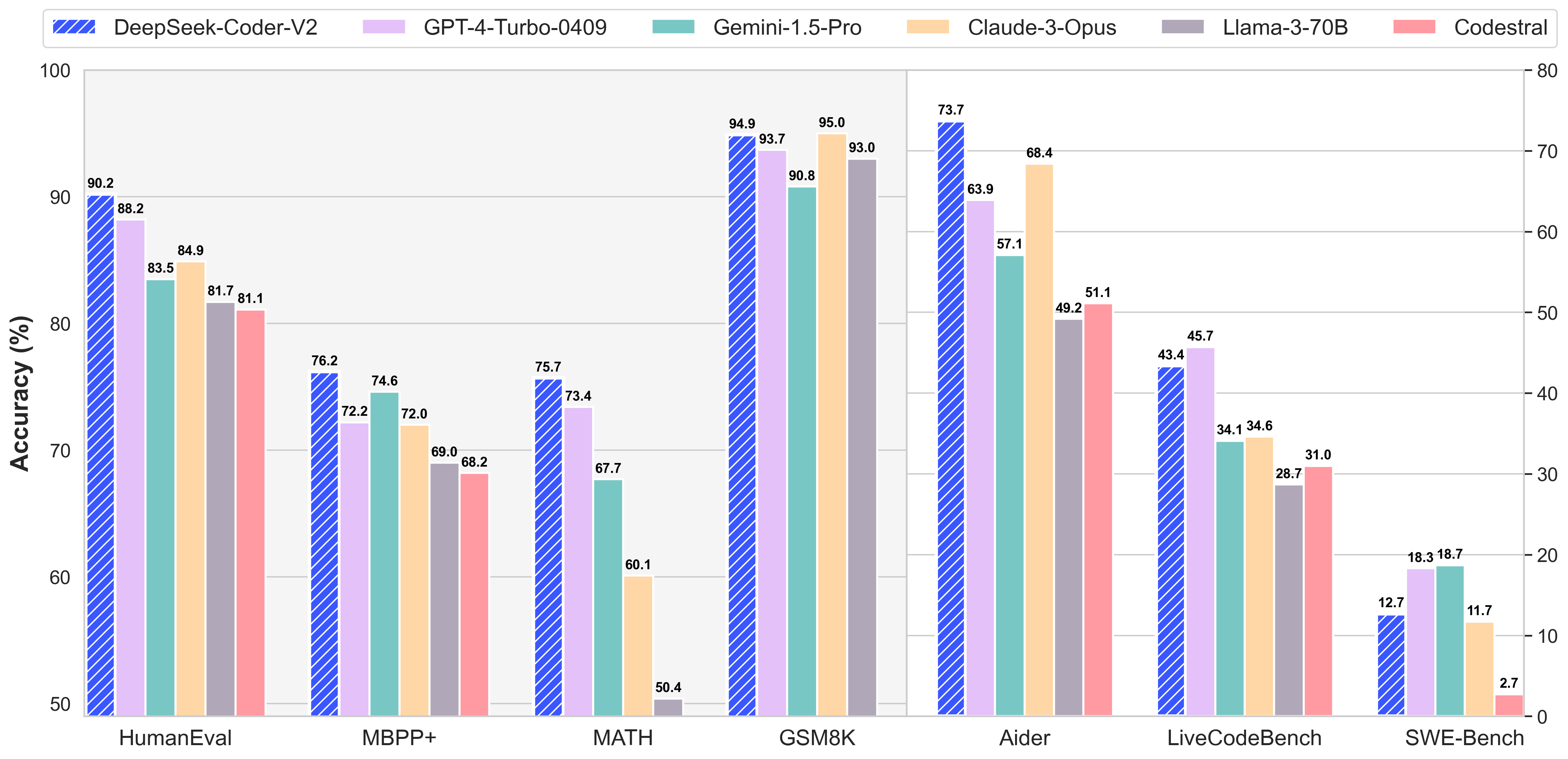
And the performance shows!
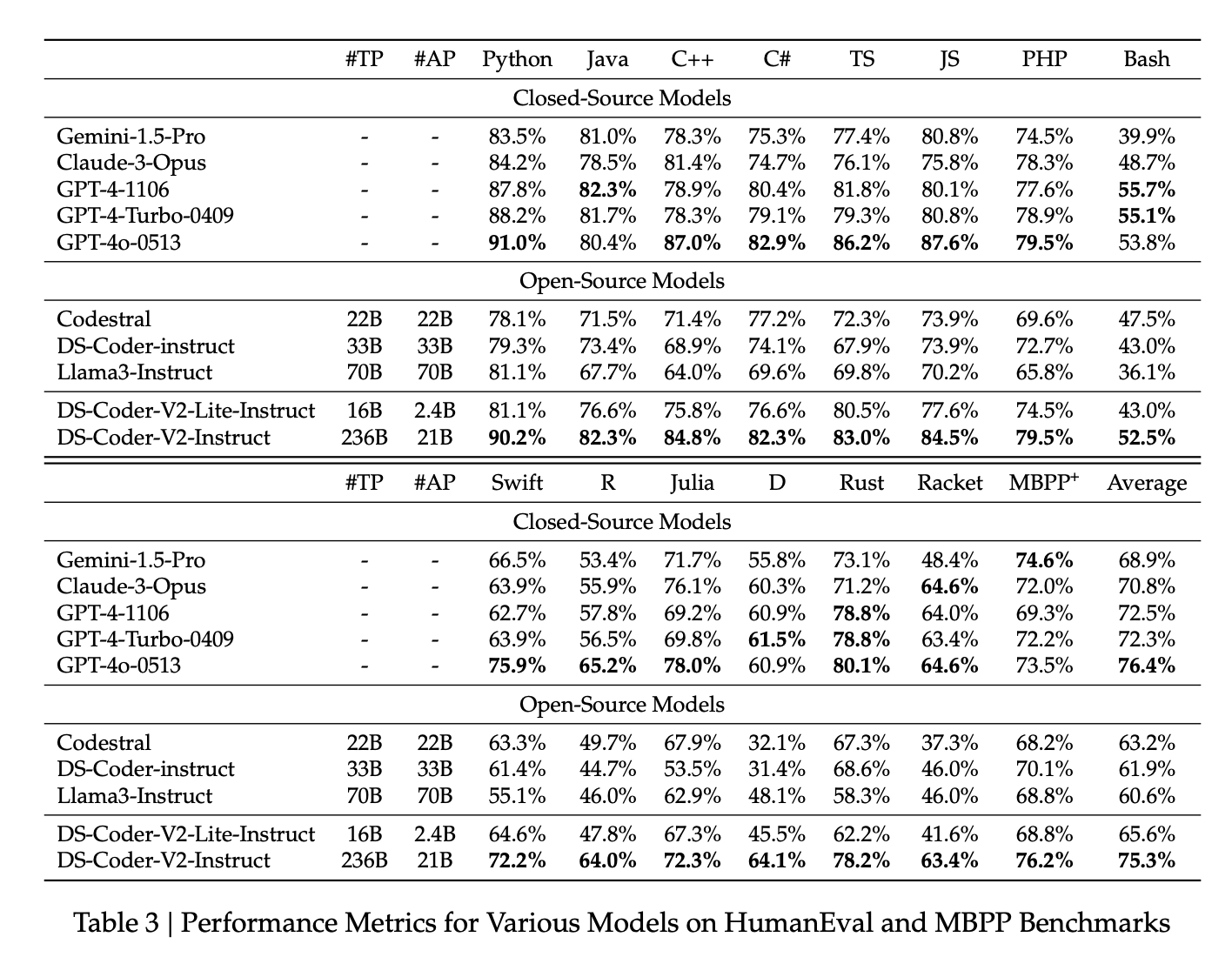
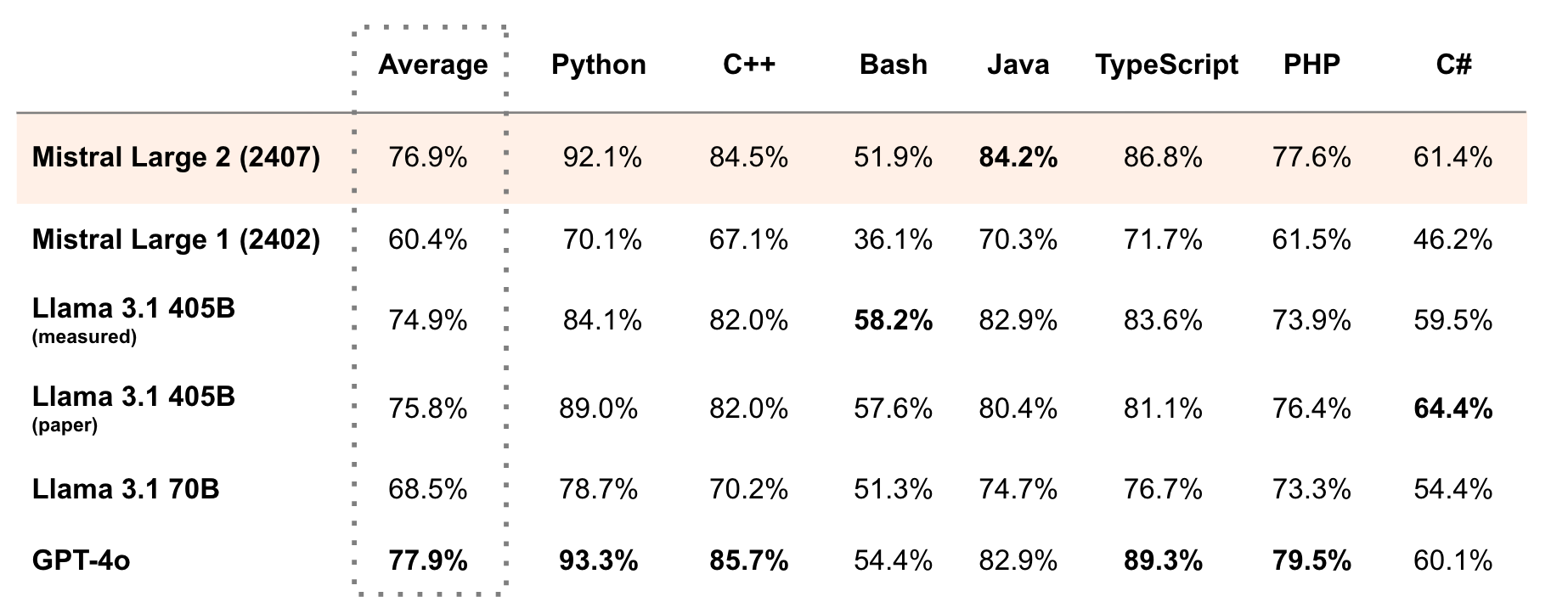
Even more recently, Mistral released an open weight model that was even better at a large number of programming tasks.2
License considerations
For companies, it’s also important to look at the licenses of each open weight and open source LLM before proceeding. For example, the Llama series of models restricts usage to organizations with fewer than 700 million daily active users.3 This basically restricts usage of tools like CodeLlama or Llama 3.1 405B at companies like Apple, Google, and Netflix. Likewise, Mistral releases its models under a research license which may make it problematic to use tools like Mistral V2 Large in commercial settings.4
Interestingly enough, DeepSeek-Coder-V2 has an exceptionally permissive license despite being released by a Beijing-based company.5 Ironically, using this model with Deepseek’s API endpoints runs the risk of exfiltrating your data to China, however, self hosting this model for commercial purposes seems to be A-OK! The model license mainly restricts users from using DeepSeek-Coder for military use and the spread of misinformation.
Setting Up a Copilot VSCode extension
The first step in getting a VSCode extension running is to find a decent plugin.
Continue.dev, Tabbyml, and SourceGraph Cody (with local serving endpoint) are all options I was able to glean from r/LocalLlama.
Based on recommendations, I decided to try out Continue.dev. The wonderful thing about this extension is that it works with any LLM that has an OpenAI compatible API endpoint.
This means you can use a tool like VLLM to setup an OpenAI-compatible server
Disabling user telemetry with Continue.dev
Continue.dev actually does collect anonymized telemetry information even on locally or self-hosted models such as the name of the model, number of tokens generated, your operating system, and IDE. However, this can actually be opted out
In the ~/.continue/config.json
{
"allowAnonymousTelemetry": false,
...
}Running a coding co-pilot Locally With Ollama
The first and most secure option is to simply run an LLM locally with Ollama. I was able to do the following with the 3 billion parameter Starcoder2, which runs decently on my (now incredibly dated) 2016 Macbook:
ollama run starcoder2:3b
Basic operations
- Tab to complete
- Highlight and
Cmd+Ito make code edits using natural language. - Highlight and
Cmd+Lto add code to a chat window.
Now, of course, being a 3b model and running on a near ancient 2016 Macbook CPU means that the autocomplete speed was sluggish at best, and the actual suggestions were downright worthless!
For example, def main() -> in python autocompleted to def main() -> int…
Running Mistral Large 2 with Nvidia NIM
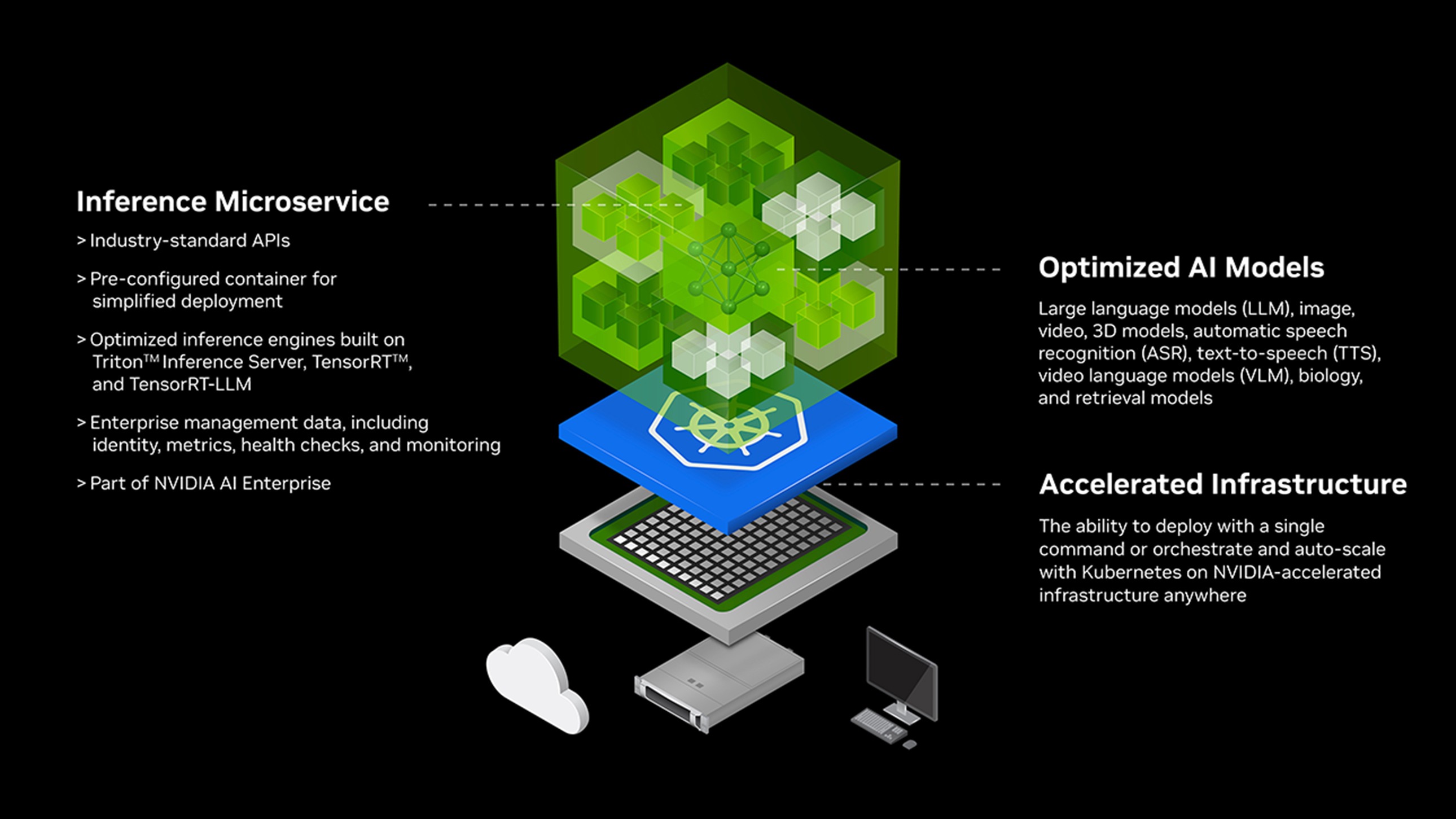
To actually get something that competes with GitHub CoPilot requires getting a bigger model. For example, the top performing DeepSeek-Coder-V2 model has over 200 billion parameters! The amount of VRAM required to run such a model exceeds even the 24GB that the Nvidia 4090 GPU can offer for anyone attempting to max out a consumer grade desktop setup.
This leaves two options - either deploying on the cloud or building a monster multi-GPU rig and setting it up as an OpenAI API compatible endpoint for a state-of-the-art LLM. Now naturally, this would end up being rather expensive and time consuming on either front.
One quicker alternative for evaluation purposes is to check out Nvidia NIMs (Nvidia Inference Microservices). NIMs are basically optimized inference microservices run by Nvidia on Nvidia hardware. Furthermore NIM services are also generally already setup with OpenAI API compatible endpoints and Nvidia TensorRT based kernel and operator fusion optimizations under the hood to “make the GPUs go Brrrr”.
At the time of writing this article, Nvidia NIM did not offer DeepSeekCoder-V2 as a microservice. However, it did offer the incredibly powerful 123B Mistral-Large-2-Instruct model which I could not help but to try out!
Using a NIM is much simpler than going through the rigamorole of deploying and optimizing an equivalent service yourself on AWS, Google Cloud, or Azure. It’s really as simple as logging into the website, getting an API token and making some API calls. And since just about every LLM on Nvidia NIM has an OpenAPI compatible endpoint, they can all be used with the Continue.dev VSCode plugin as well. Additionally, there is the added benefit that these services charge by usage rather than subscription based fee, meaning if you don’t use a copilot for a month, you generally are not charged.
The NIM documentation illustrates how to interface with the Mistral model programatically in python:
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "<PUT_YOUR_API_KEY_HERE>"
)
completion = client.chat.completions.create(
model="mistralai/mistral-large-2-instruct",
messages=[{"role":"user","content":"Write a limerick about the wonders of GPU computing."}],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")Wiring up a Mistral 2 Large NIM with Continue.dev
Wiring up a LLM for code analysis with Continue.dev is quite straightforward.
Simply edit the ~/.continue/config.json to add the model of interest
"models": [
{
"title": "Mistral 2 Large Instruct",
"provider": "openai",
"model": "mistralai/mistral-large-2-instruct",
"apiKey": "<NVIDIA_NIM_KEY>",
"apiBase": "https://integrate.api.nvidia.com/v1"
},
]When highlighting code and hitting CMD+I, a chat window will open up and analysis will hit the above API endpoint, giving you access to one of the world’s best code analysis LLMs as of the writing of this article!
Setting up tab autocomplete with Codestral 22B via Mistral
The real value-add of copilots, however is in tab autocompletion. Mistral 2 Large Instruct can be directly added to the same ~/.continue/config.json under the tabAutocompleteModel section, but this is actually not recommended. The developers of continue.dev suggest using a smaller faster model specifically targeted towards code completion like Codestral 22B.
Codestral can be used directly by setting up an account with Mistral and editing ~/.continue/config.json as follows.
"tabAutocompleteModel": {
"title": "Codestral",
"provider": "mistral",
"model": "codestral-latest",
"apiKey": "<MISTRAL_API_KEY>",
"contextLength": 32000
}Setting up tab autocomplete with Codestral 22B via Nvidia NIM
This took me a bit of trial and error, but Codestral can also be used from Nvidia NIM servers rather than Mistral servers.
There are two ways to do this:
When using mistral as a provider, note how /v1 must be ommitted from the apiBase
"tabAutocompleteModel": {
"title": "Codestral 22B Instruct v0.1",
"provider": "mistral",
"model": "mistralai/codestral-22b-instruct-v0.1",
"apiKey": "<NVIDIA_NIM_API_KEY>",
"apiBase": "https://integrate.api.nvidia.com"
}In contrast when using openai as a provider, /v1 must be included. Most all NIMs can be setup with openai as a “provider” since they offer an OpenAI API compatible endpoint.
"tabAutocompleteModel": {
"title": "Codestral 22B Instruct v0.1",
"provider": "openai",
"model": "mistralai/codestral-22b-instruct-v0.1",
"apiKey": "<NVIDIA_NIM_API_KEY>",
"apiBase": "https://integrate.api.nvidia.com/v1"
}Self Hosting on the Cloud
In the future, when I have time (and if there is interest), I may write a separate article on how to truly self-host on a public cloud. Technically speaking, using Nvidia NIMs or any other 3rd party deployment is not that different (and likely no cheaper) than simply using GPT4 or Anthropic’s Claude since data is still moving off your machine and into one of Nvidia’s cloud deployments.
Managing your own cloud deployment, although even more expensive at a small scale (since you would have to pay for passive GPU rental costs and load balancers) is a bit more secure.
For a company or organization interested in deploying the best possible open weight LLM, one tool that I would consider using is Ray Serve. Ray Serve can be used to autoscalable multi-gpu deployments on the cloud.
Furthermore Ray Serve can be used with VLLM to autogenerate an OpenAPI compatible endpoint. There is actually quite a bit of model optimization that can be used in tandem with a manual deployment like this that Nvidia NIMs take care of by default such as using Nvidia TensorRT to further optimize inference speeds.
Self Hosting with a Monster Rig
TBD when I get the time and money for a multi-gpu rig! Nvidia P40 GPUs are rather power hungry but can be had on the used market for a decent price. If I ever get around to this, I’ll make a post!
Are open source and open weight models any good for coding?
Playing around with Codestral 22B and Mistral Large 2 a bit, I can say combined they are mostly on par if not better than Github Copilot for code completion and analysis tasks. And the configurability options are quite powerful. You can arbitrarily swap out the tab autocompletion model for something bigger or smaller. You can mix and match different models like CodeLlama and different providers like Groq, Nvidia NIMs, or self-hosted options. There are even options for creating local embeddings to build knowledge bases around your local codebase to give additional context to the various copilot options. Local hosting is always an option and can be done completely off the grid, even disconnected from the internet (!). Codestral 22B (or at least one of its quantitized variants) is quite good for autocompletion, and there are probably quantized variants that can certainly be run locally on a reasonably beefy GPU equipped desktop.
Continue.dev gives you a chat window right in VSCode for any LLM open or closed.
Is it cheaper or more secure running these models on Nvidia NIMs however? The cheaper aspect is certainly questionable as I immediately burned through 4 of my free 1000 NIMs credits simply by playing around with NIMs. To gauge cost per credits requires opening an enterprise account (which I may do later this week… will update this post accordingly).
However, the basic idea of self-hosting these models in a way that at very least avoids exfiltraing code to the model creators is now quite a viable option for both individuals and companies. There’s a latent fear going through the tech community about these copilots one day subsuming the job of the professional software developer. We are still several years from this likely inevitable outcome, but having control over one’s own copilot has the slight (perhaps psychological) benefit of ensuring that the data you push to the LLM is not being used to train future iterations of it.
Citations
Zhu, Q., Guo, D., Shao, Z., Yang, D., Wang, P., Xu, R., Wu, Y., Li, Y., Gao, H., Ma, S., & others (2024). DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. Retrieved from https://arxiv.org/pdf/2406.11931 ↩︎
Mistral 2 Large Release. https://mistral.ai/news/mistral-large-2407/ ↩︎
Llama 3.1 Commercial Terms. https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE#L32C33-L33C1 ↩︎
Mistral Research License 0.1. https://mistral.ai/licenses/MRL-0.1.md ↩︎
DeepSeek-Coder Model License. https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/LICENSE-MODEL ↩︎
Related Posts

Why Big Tech Wants to Make AI Cost Nothing
Earlier this week, Meta both open sourced and released the model weights for Llama 3.1, an extraordinarily powerful large language model (LLM) which is competitive with the best of what Open AI’s ChatGPT and Anthropic’s Claude can offer.
Read more
All the Activation Functions
Recently, I embarked on an informal literature review of the advances in Deep Learning over the past 5 years, and one thing that struck me was the proliferation of activation functions over the past decade.
Read more
Python has too many package managers
Python is a wonderful programming language. I’ve used it to build webapps, deep learning models, games, and do numerical computation. However there is one aspect of Python that has been an inexcusable pain-in-the ass over many years.
Read more