
Python has too many package managers
Python is a wonderful programming language. I’ve used it to build webapps, deep learning models, games, and do numerical computation. However there is one aspect of Python that has been an inexcusable pain-in-the ass over many years. That would be the fragmented Python package and environment management ecosystem, succinctly represented by the following XKCD comic:
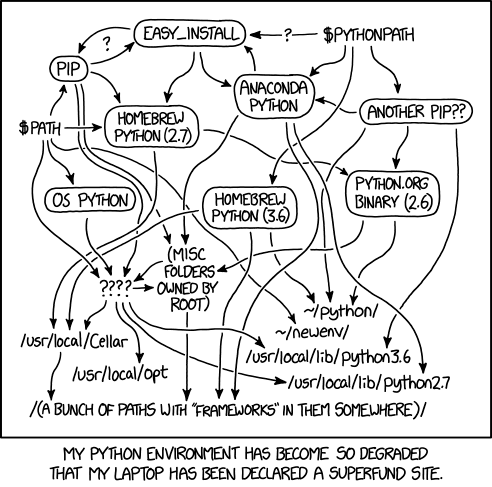
You see, a lot of other programming languages developed standardized ways to setup versioning, dependency resolution, and dev environment setup. C# has NuGet, Javascript has npm, Dart has pub, and most notably Rust has Cargo – quite possibly the most widely loved package manager tool in existence.
The sane way to do things
In a sane world, package management would work like it does with Cargo - the rust package manager. You have a single master configuration TOML file where you simply list your dependencies and config settings. The TOML file goes into a folder encapsulating your entire development environment. For extra reproducibility, whenever you build your environment and resolve all your package dependencies, a *.lock file records all the packages you used along with their versions and hashes.
Finally, because dependency resolution is a directed acylic graph (DAG) resolution problem, the dependency retrieval and resolution should both be engineered to be relatively fast. Dependency information should be freely available from a public API metadata server in a way that is simple to parse, and cached locally once downloaded to avoid redundantly hitting this server. Finally, the dependency resolution algorithm itself should be written in a relative fast programming language like C++ or Rust.
The problem with Python has been that there hasn’t been a single tool that does all of this well although some have come enticingly close. To that end, here is my rundown of more than a dozen Python package managment/virtual environment tools:
Classic Python Package Management
pip and venv
The OG of Python package managers. Dependency resolution? pip up until recently hardly did any dependency resolution at all. Historically it would install packages one by one, conflicts be damned. In version 20.3, introduced in 2020, pipfinally added dependency resolution backtracking, which means if an inconsistent state was detected, it would go back and try to fix the problem. Unlike many of the other tools in this list, and unlike tools like Cargo or NuGet in Rust and C# respectively, pip does not manage environments along with dependencies. A separate tool like venv or virtualenv needs to be used to create “virtual environments” which are in turn be completely decoupled from a specific project or project directory.
One of the key faults of pip is what happens when you decide to remove a dependency. Removing a dependency does not actually remove the sub-dependencies that were brought in by the original dependency, leaving a lot of potential cruft. This actually needs to be done either manually or by using yet another tool like pip-autoremove to remove sub-dependencies that are no longer useful.
pyenv
One thing to note about python’s venv tool is that it isn’t really setup to create virtual environments for different versions of Python. To actually do this, yet another tool called pyenv exists which allows you to switch between different versions of system Python at will, with options to set Python locally for specific projects. Very often, I’ve seen this tool abused to set Python versions globally, which can lead to some severe reproducibility issues, with folks forgetting which version of Python they were using for different projects.
pipenv
So pip and venv combined can let you build “virtual environments” and pyenv can let you switch Python versions. The natural thing to do is to have a tool that allows you to specify the python version and dependencies in a single file. pipenv basically sets this up, optionally interoperating with pyenv by letting users specify python version and dependencies in a Pipfile and locked dependencies in a Pipfile.lock.
The downside to pipenv is that it’s dependency resolution is no better than that of pip which it uses under the hood. Furthermore, in 2020, a new “Python Enhancement Proposal” PEP 621 was accepted defining how package metadata should be consolidated in the future for Python projects making Pipfile and Pipfile.lock no longer quite “idiomatic” in the long run…
Consolidating Python config with pyproject.toml and PEP-621
Before PEP-621, there were a large number of config files that could wind up in a given Python project:
requirements.txt: The project’s dependencies, which may or may not include package hashes (for security reasons) depending on how its setup.setup.pyandsetup.cfg: A script and a config file which collectively define dependencies and options.- `Pip
MANIFEST.in: Tells packaging software (like setuptools) what sort of non-code files to include in the package.tox.ini: Used by the tooltoxto configure environment setup, dependencies, and test commands (do you see the redundancy now?)PipfileandPipfile.lock: For folks usingpipenv..pylintrc: Used to setup config for linting tools likeblackandisortenvironment.yml: Used specifically by conda to define dependencies, some of which are not python packages at all. Interestingly you can specify both pip dependencies and conda dependencies separately, even if a pip package has a corresponding (and possibly better curated) version on a conda channel!.condarc: The config file for Conda.
Naturally the proliferation of all these tools and standards leads to a massive amount of redundancy. There is effectively no standard way to enumerate the dependencies of a given package nor how to setup tools like linters and tests.

In 2020 PEP 621 was accepted. This proposal effectively gives a guidance to consolidate everything into a pyproject.toml file, almost identical to Cargo.toml in Rust and similar to the package.json used in npm. Naturally this led to a proliferation of new Python package managers which leverage the new standard. Enter poetry, PDM, Flit, and Hatch.
Poetry
Poetry right now is the closest tool in the Python ecosystem with widespread traction that actually comes close to approximating the experience of using tools like Cargo and npm. Unlike pip and similar to conda and mamba (See below), Poetry will attempt to resolve the full dependency graph DAG beforehand, and install dependencies in topological order. It mostly respects pyproject.toml and treats it as a first-class citizen. Like conda and venv, poetry can also manage your virtual environments, which can exist within or outside of your project folder. poetry also generates poetry.lock files which can be an immense boon for reproducibility. Notably, these lockfiles are multi-platform lock files meaning they can be extremely large. Finally, poetry is also a build tool, allowing users to build and publish Python packages rather seamlessly.
Poetry is almost the perfect tool for the job, however it has a number of downsides that can be utter deal breakers for production or even basic research and development. First of all dependency resolution can be incredibly slow. A big part of this is no fault of poetry in of itself, but rather in the disparate ways in which Python packages enumerate their dependencies. Unlike other programming ecosystems, not all Python packages declare their metadata in a way that is necessarily served cleanly by public metadata APIs like PyPI. In these cases, exploring every dependency for every possible package in the DAG can involve a staggering amount operations to directly figure out package dependencies by downloading and parsing python wheels. For some folks doing basic R&D, the cost of simply having a few packages excluded from dependency resolution can be a fairer tradeoff than waiting minutes to hours to find a “failure to resolve dependencies”.
Furthermore, as of 2024, the dependency resolver in poetry is actually still written in Python as a depth-first search algorithm. By comparison, tools like mamba have resolvers written in C++ as boolean SAT solvers which are orders of magnitude faster! Dependency resolves for large projects in poetry, combined with the generation of multiplatform lockfiles can take an obscene amount of time… especially when there is an actual conflict in the DAG.
I have actually used poetry at my last job, and one of the number one issues with the tool is in how most folks (even incredibly experienced folks!) used it incorrectly to specify dependency bounds on library code intended to be widely shared. In poetry there is the option to use a caret ^ operator implicitly specify upper and lower bounds. For example, specifying ^0.2.3 is equivalent to specifying >=0.2.3,<0.3.0. This ceiling pinning seems like a good idea on the surface, but can wreck havok when applied across a large RnD organization, with numerous “false positive” unresolvable dependency DAGs when well-intentioned software engineers apply it too liberally. This sort of well intentioned ceiling pinning can have devastating consequences for libraries intended to be used widely.
pdm
pdm is incredibly similar to poetry, but has a core difference difference in that it also supports PEP-582. This PEP basically brings pdm in line with other programming language environment setups by jettisoning the idea of virtual environments that are independent of a given project/folder. When you are in your project directory, you are effectively in your virtual environment (which is not necessarily totally isolated from the system environment and any other active virtual environments). This can greatly reduce the futzing around of having to activate and deactivate various virtual environment tools in Python. Furthermore, pdm is much more compliant with PEP standards than poetry, which can be a killer advantage for certain users.
hatch
Unlike the other tools on this list, hatch is a full build system for python which support pyproject.toml. I have not actually tried this tool, but it mostly overlaps with poetry in many ways, and has one particular feature that I have yet to see in any other Python tool. You can actually use hatch to run tests in parallel on multiple versions of python.
The Conda ecosystem
It would be impossible to dive into an article on Python tooling without talking about Conda. conda was created by some of the most prominent members of the Python open source community - Travis Oliphant (one of the creators of Numpy, Numba, and SciPy) and Peter Wang who was a developer of Bokeh.
conda
In many ways conda and anaconda solves most of the core problems with Python environment setups for data science work. conda actually can manage non-Python dependencies along with Python packages within its own conda virtual environments. This provided a fairly ergonomic way for scientists to swap around non-python dependencies without resorting to using Docker (which is significantly higher friction to use). This is the tool I use outside of work, and it’s great for experimenting.
Like poetry, conda performs a full dependency resolve when building an environment, but unlike poetry, in recent years the conda dependency resolver has been swapped out for a faster one written in C++ called libmamba. Additionally, unlike poetry, there is no need to go and attempt to parse python packages directly when insufficient metadata was provided by upstream package maintainers. This is because conda has entirely separate metadata api servers which force package uploaders to maintain stricter standards of dependency declarations.
The core tradeoff with conda is that it attempts to do package metadata the “right” way by enforcing the existence of a separate environment.yml which properly declares dependencies and other metadata. It is actually this information which is served by conda’s separate metadata API servers. This can be onerous to adapt in a company that already has many internal python packages. If there is some obscure python package out there that does not have this file, then you won’t be able to install it using conda cleanly. However, pip installs within conda environments are possible leading to a potentially awkward mishmash of relying on two package managers. Another thing to keep in mind with conda is that it neither generates lock files out-of-the-box nor supports pyproject.toml config files.
In 2024, conda is not ideally ergonomic. Users still have to fiddle around with conda virtual environments which are decoupled from specific project folders. Dependencies and config for a project can be difficult to keep track of across conda environment.yml files, pip installs, and other configuration files. Publishing a package is neither particularly simple nor easy.
I have also seen some organizations avoid using conda for production deployments due to the fact conda tends to install a lot of cruft since it manages non-python dependencies as well. Such orgs will lean towards using Docker and *.lock style files to enumerate dependencies.
That being said, conda is probably the best tool for data scientists and experimentalists right now. It is treated as a first-class citizen by a number of third party tools widely used in the Python ecosystem such as Ray and Metaflow.
mamba
There are actually multiple implementations of conda. mamba is basically a full rewrite of conda in C++, making it substantially faster. The slowest bits of conda however were actually the solver, and as of 2024, the libmamba solver has been ported over to conda from the mamba project.
In 2024, members of the mamba team switched over to working on pixi – a full mamba and conda replacement written completely in Rust (see below).
Python Package management meets Rust
Some of the most promising developments in the Python package management world have been from the Rust community. No doubt Rustaceans have a clear example of how a package manager setup should work in the from of Cargo, and so several promising solutions have cropped up in the past 2 years, most notable of which has been uv.
huak
Just to illustrate that multiple groups have tried to make a “Cargo for Python”, I wanted to briefly mention huak. The tool is completely experimental as of the writing of this article and not widely used, but attempts to graft the ergonomics of Cargo into a python package manager.
pixi
One of the most ambitious Rust projects is pixi which seeks to be a drop-in replacement for conda. Like conda, pixi can manage non-python dependencies. In mid 2024, pixi started to switch from its own backend rip to uv (see below) for better performance. This is an actively evolving tool, and I eagerly await to see where it goes. Unlike conda and mamba, pixi incorporates its own type of *.lock file which immediately puts it ahead of vanilla conda for reproducibility.
rye
One of the first attempts to redo Python package management in Rust by Armin Ronacher. When I first saw this over a year ago, the actual slow part (dependency resolution) was simply calling piptools under the hood, leading to no discernable gain in speed or performance.
However, over time, the project has matured to the point where it now does most if not all of what poetry does only faster. This project was recently taken over by Astral.sh (developers of uv and the ruff linter) and now uses the same dependency resolver as uv on the backend. The tool has also gained a decent amount of traction on some major projects. For example, the OpenAI Python API library uses it. There is a strong possibility that the functionality of rye will eventually be fully replicated by uv alone, leading to a merging of the two projects.
uv
uv is by far the most promising package management tool in the Python ecosystem as of the writing of this post. This project actually aims to be a drop-in replacement for pip on top of being a Cargo for Python. The API is currently in no ways stable (as of 2024), but the benchmarks are incredibly promsing. Most notably, the development is backed by Astral.sh, a company formed by Charlie Marsh and the creators of the ruff linter, a widely beloved tool that virtually supplanted all incumbants overnight when it was released in 2022.
Like poetry, this project supports pyproject.toml, and like pip it uses a backtracking approach for dependency resolution. Unlike pip this algorithm is written in Rust and is very fast! Benchmarks show that uv is at least order of magnitude faster than poetry when it comes to dependency resolution. I fully expect uv to supersede tools like poetry in the future as the project matures and API stabilizes, however as of this writing, it is more of a drop-in replacement for various pip tools than an opinionated build/packaging/versioning tool like poetry or rye,
One promising sign of uv’s performance and adoption is the usage of its libraries in other package managers like pixi and rye.
Verdict
Hopefully one day there will be a cohesive solution to bring Python package management to the simplicity and ergonomics seen in the Javascript and Rust development ecosystems. Until then, I would simply recommend that most data science/experimentalists stick to using conda, and production oriented folks use pip or poetry (with some mindfulness towards slow dependency resolve for complex projects with poetry).
Fingers crossed, though, I hope uv takes off and the Python community can one day coalesce around a single standardized tool! And there are some promising signs that tools like pixi can improve on conda and its wider scoped dependency management.
Related Posts

Why Big Tech Wants to Make AI Cost Nothing
Earlier this week, Meta both open sourced and released the model weights for Llama 3.1, an extraordinarily powerful large language model (LLM) which is competitive with the best of what Open AI’s ChatGPT and Anthropic’s Claude can offer.
Read more
Host Your Own CoPilot
GitHub Co-pilot is a fantastic tool. However, it along with some of its other enterprise-grade alternatives such as SourceGraph Cody and Amazon Code Whisperer has a number of rather annoying downsides.
Read more
All the Activation Functions
Recently, I embarked on an informal literature review of the advances in Deep Learning over the past 5 years, and one thing that struck me was the proliferation of activation functions over the past decade.
Read more